工作时长和收入间的线性关系 Linear Regression
2023-06-21
3 min read
本文对KGSS 2021年的调查数据中的 Y RINCOM0收入变量 和 X WGWKHR工作时长间的线性关系进行统计检验
Data Source
- 分析工具: Python
statsmodels统计包 - 数据来源:
KGSS
Go statsmodel Document 📄 Go KGSS Data 📊
Method
- 假设 Y:
RINCOM0X:WGWKHR - 使用Python包 statsmodels 中的 OLS 线性回归函数
Import Library
import statsmodels.api as sm
import statsmodels.graphics.regressionplots as sgr
import pandas as pd
import numpy as np
Load Data
df = pd.read_spss("2003-2021_KGSS_public_v3_20230210.sav", convert_categoricals=False)
df.describe()
| YEAR | RESPID | FINALWT | KGSSAGIN | SURVEYN | SURVEFRQ | SEX | AGE | MARITAL | EMPLY | ... | HHEMPLY | HHWHYNOE | HHDNO | HOMPOP | SEPAPOP | UNRELAT | COHAP | REGION | URBAN | SAMPLEAB | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | ... | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 | 20841.000000 |
| mean | 2010.049326 | 30028.407802 | 1.000000 | -0.720215 | -0.709707 | -0.954561 | 1.540857 | 45.698575 | 2.104266 | 1.424164 | ... | 1.209011 | 0.613454 | 6.709707 | 2.900293 | 0.345665 | 0.023319 | -0.992083 | 3.429538 | 0.829327 | -0.605345 |
| std | 4.841248 | 22688.763126 | 0.459471 | 1.248061 | 0.880524 | 0.583604 | 0.498340 | 16.926672 | 1.696678 | 0.498577 | ... | 0.686990 | 3.517450 | 3.840734 | 1.303156 | 0.767434 | 0.241026 | 0.150127 | 1.824271 | 0.376232 | 0.933411 |
| min | 2003.000000 | 101.000000 | 0.203211 | -8.000000 | -8.000000 | -8.000000 | 1.000000 | -8.000000 | -8.000000 | -8.000000 | ... | -8.000000 | -8.000000 | 1.000000 | -8.000000 | -8.000000 | -8.000000 | -1.000000 | 1.000000 | 0.000000 | -1.000000 |
| 25% | 2006.000000 | 11307.000000 | 0.692861 | -1.000000 | -1.000000 | -1.000000 | 1.000000 | 33.000000 | 1.000000 | 1.000000 | ... | 1.000000 | -1.000000 | 4.000000 | 2.000000 | 0.000000 | 0.000000 | -1.000000 | 2.000000 | 1.000000 | -1.000000 |
| 50% | 2010.000000 | 25312.000000 | 0.910562 | -1.000000 | -1.000000 | -1.000000 | 2.000000 | 44.000000 | 1.000000 | 1.000000 | ... | 1.000000 | -1.000000 | 7.000000 | 3.000000 | 0.000000 | 0.000000 | -1.000000 | 4.000000 | 1.000000 | -1.000000 |
| 75% | 2013.000000 | 53405.000000 | 1.247668 | -1.000000 | -1.000000 | -1.000000 | 2.000000 | 58.000000 | 3.000000 | 2.000000 | ... | 1.000000 | -1.000000 | 10.000000 | 4.000000 | 0.000000 | 0.000000 | -1.000000 | 5.000000 | 1.000000 | -1.000000 |
| max | 2021.000000 | 70124.000000 | 4.591092 | 2.000000 | 2.000000 | 10.000000 | 2.000000 | 99.000000 | 6.000000 | 2.000000 | ... | 2.000000 | 20.000000 | 24.000000 | 11.000000 | 9.000000 | 9.000000 | 2.000000 | 7.000000 | 1.000000 | 2.000000 |
8 rows × 3212 columns
提取2021年份的数据进行分析
df_2021 = df[df.YEAR==2021]
df_2021
| YEAR | RESPID | FINALWT | KGSSAGIN | KGSSINTR | KGSSDIFF | SURVEYN | SURVEFRQ | SEX | AGE | ... | HHEMPLY | HHWHYNOE | HHDNO | HOMPOP | SEPAPOP | UNRELAT | COHAP | REGION | URBAN | SAMPLEAB | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 19636 | 2021.0 | 101.0 | 0.567077 | 1.0 | -1 | -1 | 2.0 | -1.0 | 2.0 | 36.0 | ... | 1.0 | -1.0 | 1.0 | 1.0 | 0.0 | 1.0 | -1.0 | 1.0 | 1.0 | 1.0 |
| 19637 | 2021.0 | 102.0 | 0.342096 | 2.0 | -1 | -1 | 2.0 | -1.0 | 2.0 | 63.0 | ... | 1.0 | -1.0 | 2.0 | 1.0 | 0.0 | 0.0 | -1.0 | 1.0 | 1.0 | 2.0 |
| 19638 | 2021.0 | 104.0 | 0.588853 | 1.0 | -1 | -1 | 2.0 | -1.0 | 2.0 | 26.0 | ... | 1.0 | -1.0 | 4.0 | 1.0 | 0.0 | 0.0 | -1.0 | 1.0 | 1.0 | 2.0 |
| 19639 | 2021.0 | 105.0 | 0.689820 | -8.0 | -1 | -1 | -8.0 | -1.0 | 1.0 | 32.0 | ... | 1.0 | -1.0 | 5.0 | 1.0 | 0.0 | 0.0 | -1.0 | 1.0 | 1.0 | 1.0 |
| 19640 | 2021.0 | 106.0 | 0.850229 | -8.0 | -1 | -1 | 2.0 | -1.0 | 1.0 | 27.0 | ... | 1.0 | -1.0 | 6.0 | 1.0 | 0.0 | 0.0 | -1.0 | 1.0 | 1.0 | 2.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20836 | 2021.0 | 70104.0 | 1.009292 | 2.0 | -1 | -1 | 2.0 | -1.0 | 2.0 | 35.0 | ... | 1.0 | -1.0 | 4.0 | 4.0 | 0.0 | 0.0 | -1.0 | 4.0 | 1.0 | 2.0 |
| 20837 | 2021.0 | 70105.0 | 1.107223 | 2.0 | -1 | -1 | 2.0 | -1.0 | 2.0 | 47.0 | ... | 1.0 | -1.0 | 5.0 | 4.0 | 0.0 | 0.0 | -1.0 | 4.0 | 1.0 | 1.0 |
| 20838 | 2021.0 | 70106.0 | 1.604723 | 2.0 | -1 | -1 | 2.0 | -1.0 | 1.0 | 58.0 | ... | 1.0 | -1.0 | 6.0 | 4.0 | 0.0 | 0.0 | -1.0 | 4.0 | 1.0 | 2.0 |
| 20839 | 2021.0 | 70109.0 | 1.255510 | 2.0 | -1 | -1 | 2.0 | -1.0 | 1.0 | 33.0 | ... | 1.0 | -1.0 | 9.0 | 2.0 | 0.0 | 0.0 | -1.0 | 4.0 | 1.0 | 1.0 |
| 20840 | 2021.0 | 70111.0 | 1.107223 | -8.0 | -1 | -1 | 1.0 | -8.0 | 2.0 | 47.0 | ... | 1.0 | -1.0 | 11.0 | 3.0 | 0.0 | 0.0 | -1.0 | 4.0 | 1.0 | 1.0 |
1205 rows × 3215 columns
Pre-process
WGWKHR
df_2021.WGWKHR.describe()
count 1205.000000
mean 13.727801
std 20.376129
min -8.000000
25% -1.000000
50% -1.000000
75% 40.000000
max 80.000000
Name: WGWKHR, dtype: float64
统计异常值总和
sum(df_2021["WGWKHR"]==-8)
7
将异常值替换为空(np.nan)
WGWKHR = df_2021["WGWKHR"]
WGWKHR.replace((-8,-1), np.nan, inplace=True)
WGWKHR.describe()
/var/folders/pm/fx5ldf494tqd843k9mpzck740000gn/T/ipykernel_2294/3763845172.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
WGWKHR.replace((-8,-1), np.nan, inplace=True)
count 476.000000
mean 36.386555
std 14.185602
min 2.000000
25% 35.000000
50% 40.000000
75% 45.000000
max 80.000000
Name: WGWKHR, dtype: float64
RINCOM
RINCOM = df_2021["RINCOM0"]
RINCOM.describe()
count 1205.000000
mean 174.807469
std 211.070790
min -8.000000
25% -1.000000
50% 150.000000
75% 300.000000
max 2400.000000
Name: RINCOM0, dtype: float64
替换异常值
RINCOM.replace((-8,-1), np.nan, inplace=True)
RINCOM.describe()
/var/folders/pm/fx5ldf494tqd843k9mpzck740000gn/T/ipykernel_2294/3581387875.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
RINCOM.replace((-8,-1), np.nan, inplace=True)
count 730.000000
mean 289.547945
std 200.331463
min 0.000000
25% 190.000000
50% 250.000000
75% 350.000000
max 2400.000000
Name: RINCOM0, dtype: float64
收入数据方差过大,容易对线性模型产生影响,因此将RINCOMlog标准化
RINCOM = np.log(RINCOM).replace(-np.inf,0)
RINCOM.describe()
/Users/jmsu/anaconda3/envs/KGSS/lib/python3.10/site-packages/pandas/core/arraylike.py:402: RuntimeWarning: divide by zero encountered in log
result = getattr(ufunc, method)(*inputs, **kwargs)
count 730.000000
mean 5.394227
std 1.001719
min 0.000000
25% 5.247024
50% 5.521461
75% 5.857933
max 7.783224
Name: RINCOM0, dtype: float64
Simaple Linear Regression (OLS)
建立模型,拟合并输出结果
model = sm.OLS(RINCOM, sm.add_constant(WGWKHR),missing='drop')
result = model.fit()
result.summary()
| Dep. Variable: | RINCOM0 | R-squared: | 0.117 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.115 |
| Method: | Least Squares | F-statistic: | 60.54 |
| Date: | Wed, 21 Jun 2023 | Prob (F-statistic): | 4.81e-14 |
| Time: | 18:14:13 | Log-Likelihood: | -464.72 |
| No. Observations: | 461 | AIC: | 933.4 |
| Df Residuals: | 459 | BIC: | 941.7 |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 4.8424 | 0.086 | 56.061 | 0.000 | 4.673 | 5.012 |
| WGWKHR | 0.0172 | 0.002 | 7.781 | 0.000 | 0.013 | 0.021 |
| Omnibus: | 306.448 | Durbin-Watson: | 1.707 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 6747.756 |
| Skew: | -2.490 | Prob(JB): | 0.00 |
| Kurtosis: | 21.069 | Cond. No. | 109. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
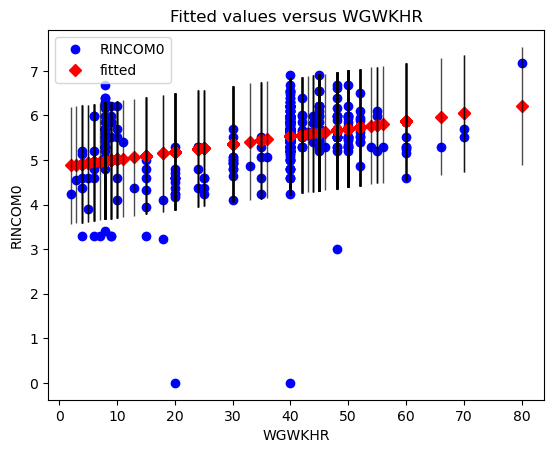
可以看出 说明模型的拟合程度不足,很好解释,因为很明显自变量
工作时长不是影响因变量收入的唯一因素, 需要其他变量的介入,拟合多元线性模型以提高解释能力。
根据参数t检验结果,可以看出
工作时长与收入间的存在着显著的线性关系
画个回归拟合图:
sgr.plot_fit(result, 1)